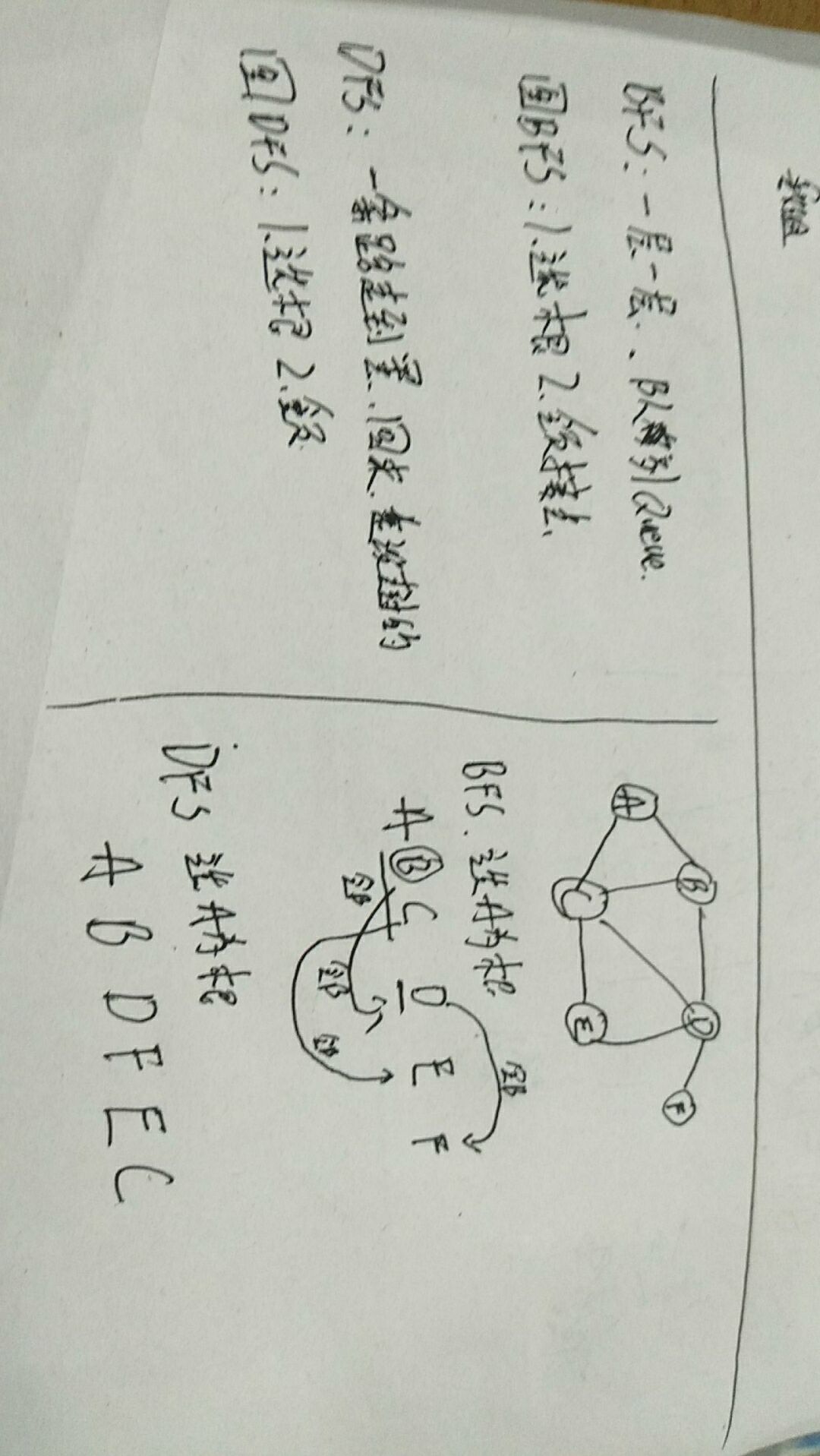
BFS
代码步骤:
1、写出每个点和每个点的邻接点的对应关系
2、方法参数:传一个对应关系和起始点
3、创建一个队列,然后每次都移除第一个,然后把移除的邻接点添加进去,打印取出的第一个,然后循环,一直到队列没有元素


import java.util.ArrayList;import java.util.HashMap;import java.util.HashSet;import java.util.List;import java.util.Map;import java.util.Set;public class BFS { public static void main(String[] args) { List list = new ArrayList();//A的邻接点 list.add("B"); list.add("C"); List list2 = new ArrayList();//B的邻接点 list2.add("A"); list2.add("C"); list2.add("D"); List list3 = new ArrayList();//C的邻接点 list3.add("A"); list3.add("B"); list3.add("D"); list3.add("E"); List list4 = new ArrayList();//D的邻接点 list4.add("B"); list4.add("C"); list4.add("E"); list4.add("F"); List list5 = new ArrayList();//E的邻接点 list5.add("C"); list5.add("D"); List list6 = new ArrayList();//F的邻接点 list6.add("D"); Map map = new HashMap<>();//使得邻接点和该值对应上 map.put("A", list); map.put("B", list2); map.put("C", list3); map.put("D", list4); map.put("E", list5); map.put("F", list6); BFS(map,"E"); } /** * 利用对列的方式 * @param map 字典 * @param s 根节点 */ public static void BFS(Map map,String s){ List queue = new ArrayList();//队列 queue.add(s); ArrayList seen = new ArrayList();//用来放已经访问过的元素 seen.add(s); while(queue.size()>0) { //队列没有元素位置 String vertex = (String) queue.remove(0);//每次取队列第一个元素 List nodes = (List) map.get(vertex);//把vertex所有临近点 for(String w:nodes) { //遍历所有邻接点,没有包含的进入队列 if(!seen.contains(w)) { queue.add(w); seen.add(w); } } System.out.println(vertex); } } }
BFS的最短路径
就是添加一个键值对,键就是该字母,值就是他的前一个字母
import java.util.ArrayList;import java.util.HashMap;import java.util.HashSet;import java.util.List;import java.util.Map;import java.util.Set;public class BFS最短路径 { public static void main(String[] args) { List list = new ArrayList(); list.add("B"); list.add("C"); List list2 = new ArrayList(); list2.add("A"); list2.add("C"); list2.add("D"); List list3 = new ArrayList(); list3.add("A"); list3.add("B"); list3.add("D"); list3.add("E"); List list4 = new ArrayList(); list4.add("B"); list4.add("C"); list4.add("E"); list4.add("F"); List list5 = new ArrayList(); list5.add("C"); list5.add("D"); List list6 = new ArrayList(); list6.add("D"); Map map = new HashMap<>(); map.put("A", list); map.put("B", list2); map.put("C", list3); map.put("D", list4); map.put("E", list5); map.put("F", list6); BFS(map,"A"); } /** * 利用对列的方式 * @param map * @param s */ public static void BFS(Map map,String s){ List queue = new ArrayList();//队列 queue.add(s); ArrayList seen = new ArrayList();//用来放已经访问过的元素 seen.add(s); Map parent = new HashMap(); parent.put(s, null); while(queue.size()>0) { String vertex = (String) queue.remove(0);//那队列第一个元素 List nodes = (List) map.get(vertex);//把vertex所有临近点 for(String w:nodes) { //遍历所有邻接点,没有包含的进入队列 if(!seen.contains(w)) { queue.add(w); seen.add(w); parent.put(w, vertex);//添加字符前一个字符 } } //System.out.println(vertex); } //输出最短路径 String end = "E"; while(end!=null) { System.out.println(end); end = (String) parent.get(end); } } }
DFS
就是把BFS的队列换成栈,根本区别就是变成移除最后一个了
import java.util.ArrayList;import java.util.HashMap;import java.util.HashSet;import java.util.List;import java.util.Map;import java.util.Set;public class DFS { public static void main(String[] args) { List list = new ArrayList(); list.add("B"); list.add("C"); List list2 = new ArrayList(); list2.add("A"); list2.add("C"); list2.add("D"); List list3 = new ArrayList(); list3.add("A"); list3.add("B"); list3.add("D"); list3.add("E"); List list4 = new ArrayList(); list4.add("B"); list4.add("C"); list4.add("E"); list4.add("F"); List list5 = new ArrayList(); list5.add("C"); list5.add("D"); List list6 = new ArrayList(); list6.add("D"); Map map = new HashMap<>(); map.put("A", list); map.put("B", list2); map.put("C", list3); map.put("D", list4); map.put("E", list5); map.put("F", list6); DFS(map,"E"); } /** * 利用对列的方式 * @param map * @param s */ public static void DFS(Map map,String s){ List stack = new ArrayList();//栈 stack.add(s); ArrayList seen = new ArrayList();//用来放已经访问过的元素 seen.add(s); while(stack.size()>0) { String vertex = (String) stack.remove(stack.size()-1);//拿队列最后一个元素 List nodes = (List) map.get(vertex);//把vertex所有临近点 for(String w:nodes) { //遍历所有邻接点,没有包含的进入队列 if(!seen.contains(w)) { stack.add(w); seen.add(w); } } System.out.println(vertex); } } }